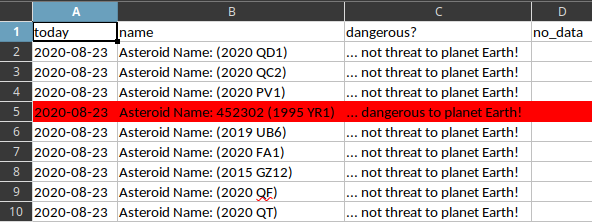
I used three files created with LibreOffice and save it like xlsx file type.
All of these files come with the column A fill with strings of characters, in this case, numbers.
The script will read all of these files from the folder named xlsx_files and will calculate Levenshtein ratio and distance between the strings of name of these files and column A.
Finally, the result is shown into a graph with matplotlib python package.
Let's see the python script:
import os
from glob import glob
from openpyxl import load_workbook
import numpy as np
import matplotlib.pyplot as plt
def levenshtein_ratio_and_distance(s, t, ratio_calc = False):
""" levenshtein_ratio_and_distance - distance between two strings.
If ratio_calc = True, the function computes the
levenshtein distance ratio of similarity between two strings
For all i and j, distance[i,j] will contain the Levenshtein
distance between the first i characters of s and the
first j characters of t
"""
# Initialize matrix of zeros
rows = len(s)+1
cols = len(t)+1
distance = np.zeros((rows,cols),dtype = int)
# Populate matrix of zeros with the indeces of each character of both strings
for i in range(1, rows):
for k in range(1,cols):
distance[i][0] = i
distance[0][k] = k
for col in range(1, cols):
for row in range(1, rows):
# check the characters are the same in the two strings in a given position [i,j]
# then the cost is 0
if s[row-1] == t[col-1]:
cost = 0
else:
# calculate distance, then the cost of a substitution is 1.
if ratio_calc == True:
cost = 2
else:
cost = 1
distance[row][col] = min(distance[row-1][col] + 1, # Cost of deletions
distance[row][col-1] + 1, # Cost of insertions
distance[row-1][col-1] + cost) # Cost of substitutions
if ratio_calc == True:
# Ration computation of the Levenshtein Distance Ratio
Ratio = ((len(s)+len(t)) - distance[row][col]) / (len(s)+len(t))
return Ratio
else:
return distance[row][col]
PATH = "/home/mythcat/xlsx_files/"
result = [y for x in os.walk(PATH) for y in glob(os.path.join(x[0], '*.xlsx'))]
result_files = [os.path.join(path, name) for path, subdirs, files in os.walk(PATH) for name in files]
#print(result)
row_0 = []
for r in result:
n = 0
wb = load_workbook(r)
sheets = wb.sheetnames
ws = wb[sheets[n]]
for row in ws.rows:
if (row[0].value) != None :
rows = row[0].value
row_0.append(rows)
print("All rows of column A ")
print(row_0)
files = []
for f in result_files:
ff = str(f).split('/')[-1:][0]
fff = str(ff).split('.xlsx')[0]
files.append(fff)
print(files)
# define tree lists for levenshtein
list1 = []
list2 = []
for l in row_0:
str(l).lower()
for d in files:
Distance = levenshtein_ratio_and_distance(str(l).lower(),str(d).lower())
Ratio = levenshtein_ratio_and_distance(str(l).lower(),str(d).lower(),ratio_calc = True)
list1.append(Distance)
list2.append(Ratio)
print(list1, list2)
# plotting the points
plt.plot(list1,'g*', list2, 'ro' )
plt.show()[mythcat@desk ~]$ python test_xlsx.py
All rows of column A
[11, 2, 113, 4, 1111, 4, 4, 111, 2, 1111, 5, 4, 4, 3, 1111, 1, 2, 1113, 4, 115, 1, 2, 221, 1, 1,
43536, 2, 34242, 3, 1]
['001', '002', '003']
[2, 3, 3, 3, 2, 3, 3, 3, 2, 3, 3, 3, 3, 4, 4, 3, 3, 3, 3, 3, 3, 2, 3, 3, 3, 2, 3, 3, 4, 4, 3, 3,
3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 3, 4, 4, 2, 3, 3, 3, 2, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 2, 3, 3, 3,
2, 3, 2, 3, 3, 2, 3, 3, 2, 3, 3, 5, 5, 4, 3, 2, 3, 5, 4, 5, 3, 3, 2, 2, 3, 3] [0.4, 0.0, 0.0, 0.0,
0.5, 0.0, 0.3333333333333333, 0.0, 0.3333333333333333, 0.0, 0.0, 0.0, 0.2857142857142857, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3333333333333333, 0.0, 0.0, 0.0, 0.5, 0.0, 0.2857142857142857, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.5, 0.2857142857142857, 0.0, 0.0, 0.5,
0.0, 0.0, 0.0, 0.5, 0.0, 0.2857142857142857, 0.0, 0.2857142857142857, 0.0, 0.0, 0.0, 0.3333333333333333,
0.0, 0.0, 0.5, 0.0, 0.0, 0.0, 0.5, 0.0, 0.3333333333333333, 0.3333333333333333, 0.0, 0.5, 0.0, 0.0,
0.5, 0.0, 0.0, 0.0, 0.0, 0.25, 0.0, 0.5, 0.0, 0.0, 0.25, 0.25, 0.0, 0.0, 0.5, 0.5, 0.0, 0.0]