[mythcat@desk django]$ source env/bin/activate(env) [mythcat@desk django]$ pip3 install --upgrade django --user
Collecting django
...
Successfully uninstalled Django-3.0
Successfully installed django-3.0.1(env) [mythcat@desk django]$ pip3 install djangorestframework --user
Collecting djangorestframework
...
Installing collected packages: djangorestframework
Successfully installed djangorestframework-3.11.0(env) [mythcat@desk django]$ cd mysite/
(env) [mythcat@desk mysite]$ python3 manage.py makemigrations
No changes detected
(env) [mythcat@desk mysite]$ python3 manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, sessions, test001
Running migrations:
No migrations to apply.The Django implements serializers for this.
Serializers provide deserialization, allowing parsed data to be converted back into complex types and allow complex data such as querysets and model instances to be converted to native Python datatypes that can then be easily rendered into JSON, XML or other content types.
Let's create the mysite/serializers.py:
(env) [mythcat@desk mysite]$ cd mysite/
(env) [mythcat@desk mysite]$ vim serializers.py from django.contrib.auth.models import User, Group
from rest_framework import serializers
class UserSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = User
fields = ['url', 'username', 'email', 'groups']
class GroupSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model = Group
fields = ['url', 'name']My urls.py file from the Django-chart project is this:
from django.contrib import admin
from django.urls import path
from test001.views import home_page
from test001.views import Test001ChartView
#
from django.urls import include, path
from rest_framework import routers
from test001 import views
router = routers.DefaultRouter()
router.register(r'users', views.UserViewSet)
router.register(r'groups', views.GroupViewSet)
app_name = 'test001'
urlpatterns = [
path('admin/', admin.site.urls),
#path('', home_page, name ='home'),
path('', Test001ChartView.as_view(), name = 'home'),
# Use automatic URL routing
# Can also include login URLs for the browsable API
path('', include(router.urls)),
path('api-auth/', include('rest_framework.urls', namespace='rest_framework'))
]from django.http import HttpResponse
from django.shortcuts import render
# snippet
from django.shortcuts import get_object_or_404
# for chart
from django.views.generic import TemplateView
from .models import Test001, Snippet
#
#def home_page(request):
# return HttpResponse('Home page!')
# django framework
from django.contrib.auth.models import User, Group
from rest_framework import viewsets
from mysite.serializers import UserSerializer, GroupSerializer
def home_page(request):
return render(request, 'test001/home.html',{
'name':'CGF',
'html_items': ['a','b','c','d','e']
})
# define view for chart
class Test001ChartView(TemplateView):
template_name = 'test001/chart.html'
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context["qs"] = Test001.objects.all()
return context
def snippet_detail(request, id):
snippet = get_object_or_404(Snippet, id=id)
return render(request, 'test001/snippets_detail.html', {'snippet': snippet})
class UserViewSet(viewsets.ModelViewSet):
"""
API endpoint allows users to be viewed or edited.
"""
queryset = User.objects.all().order_by('-date_joined')
serializer_class = UserSerializer
class GroupViewSet(viewsets.ModelViewSet):
"""
API endpoint allows groups to be viewed or edited.
"""
queryset = Group.objects.all()
serializer_class = GroupSerializerINSTALLED_APPS = [
...
'rest_framework',
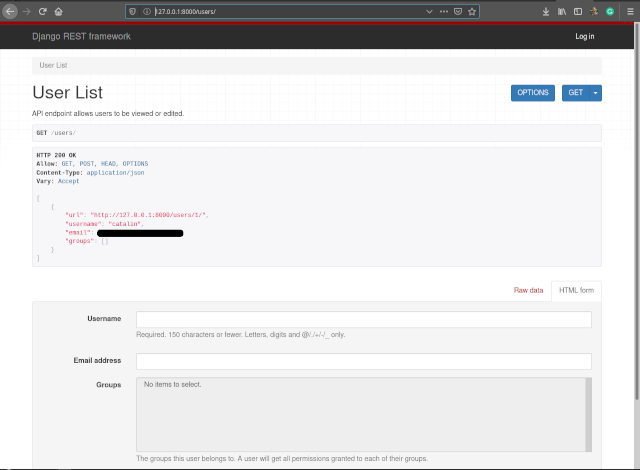
]python3 manage.py runserver